关于增加skynet_fly orm数据关系映射
ORM简介
ORM(Object-Relational Mapping,对象关系映射)是一种编程技术,用于在不同类型的系统之间转换数据。在关系数据库和面向对象编程语言之间,ORM 为数据的转换提供了一个桥梁。这种技术允许我们使用编程语言中的对象表示和操作数据库中的数据,而不必编写底层的SQL代码。
ORM 的核心优势在于抽象化和自动化数据存储的细节,使开发者可以专注于业务逻辑,而无需关心数据库操作的具体实现。
ORM 的主要功能包括:
映射(Mapping):将数据库表(或视图)映射到代码中的类,将记录映射到对象实例,列映射到类的属性。
CRUD 操作:提供了对象级别的创建(Create)、读取(Read)、更新(Update)和删除(Delete)操作,不需要直接使用SQL语句。
查询接口:提供了建立在对象上的查询接口,允许我们使用类似SQL功能的方法来查询和操作数据。
事务管理:支持事务操作,确保数据一致性和完整性。
缓存:为了性能优化,ORM系统通常提供了一级或二级缓存机制,减少对数据库的直接访问次数。
ORM 的优点:
- 生产效率:通过简化数据库操作,ORM 可以提高开发速度。
- 可维护性:代码通常更清晰、更可维护,因为它遵循面向对象的原则。
- 可移植性:ORM 代码通常不依赖于具体的数据库,更容易在不同的数据库系统之间移植。
- 减少重复:ORM 库通常提供了大量公共代码,减少开发人员需要编写和维护的代码量。
ORM 的缺点:
- 性能开销:ORM 增加了一层抽象,可能会导致性能开销,尤其是在复杂查询和高负载操作的情况下。
- 复杂性:在处理复杂的查询或性能优化时,ORM 可能不如使用原生 SQL 灵活。
- 学习曲线:需要学习使用 ORM 工具或框架,了解其设计和最佳实践。
skynet_fly ORM提供功能
- 映射提供。
- CRUD操作提供。
- 提供主键查询和查询所有。
- 不支持事务,确保数据一致性和完整性。
- 缓存,提供缓存时间和永久缓存机制,定时批量同步修改。
实现orm的目标是能够应付非常常见的功能数据,比如跟玩家id,角色id关联的数据。并不想适配比较复杂的需求场景,比如分页查询,条件查询等等。这样orm能够更好的适配数据库,比如mysql,redis,mongo等等。
这样能够简化实现,方便后续维护优化,也不用担心性能问题(因为不能通过orm做复杂的查询工作),复杂性也没有了,学习也很简单,因为只有 CRUD 和通过主键查询的接口,并且通过主键查询的也是可以落入缓存的。
实现方案
实现上通过依赖反转的方式,通过抽象出数据适配器接口,让数据表实体依赖数据适配器接口,这样想对接不同的数据库,只需要实现数据适配器接口就行。
结构图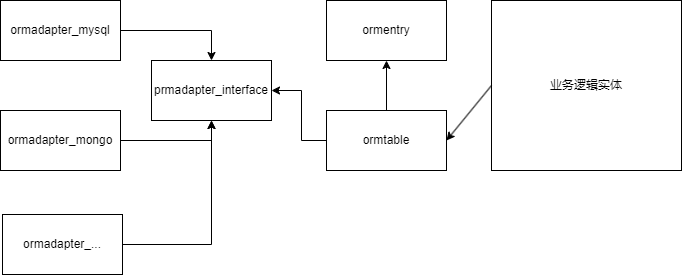
创建表
数据类型支持。
1 | |
不支持浮点型,因为浮点型有精度问题,而且系统,语言的处理可能都不一样,业务上尽量不用。
不支持bool类型,业务上直接用int8类型替代就行了。
创建表示例
1 | |
一开始想法是用写lua表字段描述的方式来创建比如:
1 | |
后来想想这种用 建造者模式更适合。
优点
- 不需要写name,type描述字段,而且类型的函数没有时或者检查有错,直接在对应的行就报错了,更有利于开发。
- 能够设置一些额外属性,比如set_cache,设置缓存时间。
- 代码结构更清晰。
修改表
通常在实际业务开发中,可能由于需求的变化,想要改动表结构,大部分情况都是新增字段,orm提供修改表的手段,提供新增字段,删除字段。
不可以删除或者修改主键,也不可以修改关联主键顺序。
修改示例
修改表并不需要调用其他API,使用中,只需要去调整创建过程即可。
基于上面的创建示例,修改示例如下。
1 | |
这个修改示例中,我们去掉了多余不想用的字段,增加了nickname1字段。
删除字段并不会真的去对应数据库执行删除字段(这个是ormadapter接口实现决定的),只是orm不在关心该字段,查询不取,插入不写。
字段默认值
当我们没有为字段设置值的时候,字段提供默认值。
对于lua是string类型的默认为空串,也就是””
对于lua是number类型的默认为0
创建数据
1 | |
支持一次创建多条。
读取数据
1 | |
利用关联主键,使用最左原则查询数据。
修改更新数据
1 | |
修改数据有个限制,主键不能修改(正常也不会去改主键)。
更新数据也可以不用主动调用save_entry,可以用set_cache设置缓存,同时设置间隔多少秒去同步,这种方式效率更高,因为是定时批量同步的。
删除数据
删除数据类似读取数据通过主键keys去删除。
1 | |
适配
目前针对orm适配了mysql,后续会适配mango。适配器需要实现六个方法分别是:new,builder,create_entry,get_entry,save_entry,delete_entry。
- new, 创建适配器对象。
- builder(tab_name, filed_list, filed_map, key_list) 构建表。
- create_entry(entry_data_list) 创建表数据。
- get_entry(key_values) 查询表数据。
- save_entry(entry_data_list, change_map_list) 保存表数据。
- delete_entry(key_values) 删除表数据。
适配mysql
针对适配MySQL,我的设计是这样的,在builder构建方法中,表不存在创建表,表存在更新表,主键不能为空,主键不能变更修改。
在create_entry和save_entry中做了批量安全处理(消息过长的分批执行)。
单元测试
针对ormmysql写了健全的单元测试。
ormmysqltest
总结
为框架增加了orm特性的支持。增强了skynet_fly的功能。
使用orm的限制
使用orm需要注意数据一致性问题。orm只能在一个服务中使用才能保证一致性。特别是使用缓存的时候,不用缓存,在多个服务同时用,也需要考虑分布式问题(不用orm多个服务也存在分布式问题)。
有一种情况下可以多服使用:比如用player_id绑定服务器,并且服务器只会查询修改连接本服的player_id的数据。
其他情况需要在一个服务中处理,后续想利用框架的热更模块对接上orm,并且处理好热更问题。因为热更过程中可能新旧服务都持有数据的,可能出现数据不一致,目前的想法是热更后,旧服务的请求全部转给新服务处理,旧服务收到准备下线的时候,保存所有数据,并拒绝之后所有的请求,通知等待新服上线处理,就可以解决这个问题。
orm的缓存策略
面对高并发的场景,我们需要尽量减少访问数据库,skynet_fly提供了设置缓存时间、改动统一同步的设置项。
比如设置5秒缓存,1秒同步一次修改。 set_cache(500,100)。
orm会在创建和查询的时间重置一下缓存。这样可以尽可能保留热数据的缓存不失效。
缓存优化 2024/3/17
由于之前的缓存,没有考虑缓存总量控制,当缓存时长过长,缓存量大的时候,会导致服务器内存增长不可控。所以需要引入缓存淘汰策略来控制缓存总量。
常见的缓存淘汰策略有:
- LRU 最近最少使用淘汰算法(Least Recently Used)。LRU是淘汰最长时间没有被使用的数据
- LFU 最不经常使用淘汰算法(Least Frequently Used)。LFU是淘汰一段时间内,使用次数最少的数据
- TTI 最快过期淘汰
由于目前以有缓存时间,就打算先实现TTI的策略,后续有想法再引入LRU,LFU。
缓存穿透问题优化 2024/3/24
缓存常见3大问题
缓存雪崩 大量热点数据同时过期,导致大量请求落到数据库。
常见的解决方案
过期时间增加额外的随机数,使过期时间分散。
skynet_fly解决方案
创建和查询,都会使过期时间重置,热点数据在这种机制下不可能大量同时过期。缓存击穿 单个热点数据存在大量请求,数据过期后,大量请求落到数据库。
常见的解决方案
定量热点数据不设置过期时间。
skynet_fly解决方案
提供设置不过期手段。
查询重置过期时间。
所有请求都要经过orm代理,就算过期了,经过queue的排队处理,也只有一条请求落到数据库,之后的请求都能命中缓存。缓存穿透 查询数据库不存在的数据,一般缓存也不会建立。导致大量请求落到数据库。
常见的解决方案
布隆过滤器(存在误判)。
建立空缓存。
skynet_fly解决方案
建立空缓存,因为大部分业务是需要精准判断的。
针对不过期缓存的优化,既然缓存不过期,那边orm初始化的时候可以把数据库的所有数据拉取出来建立缓存。之后查询,如果缓存不存在那么就是不存在。