skynet c层的整体架构
架构图
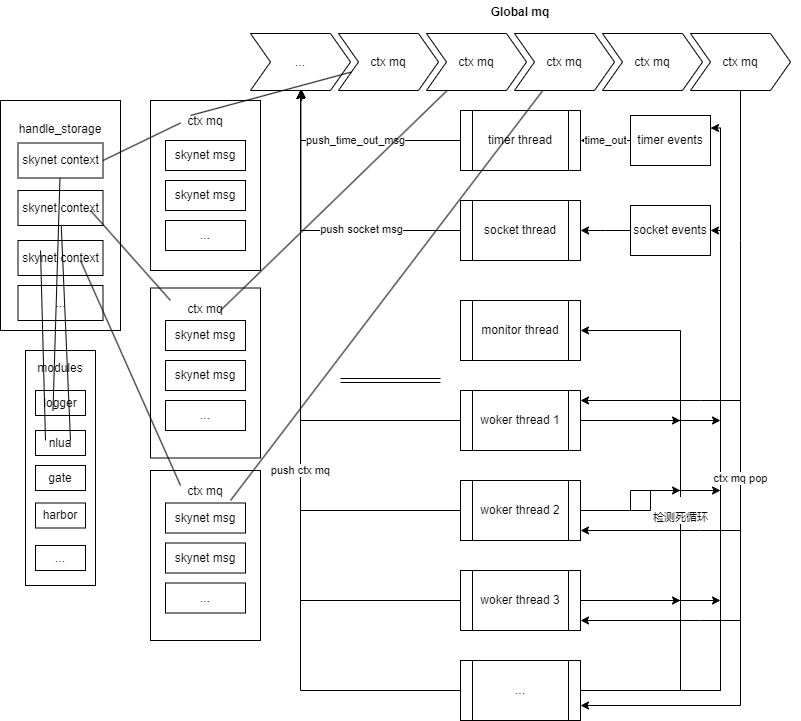
上图是skynet框架的核心的架构图,看完整体我们再去细看内部实现细节,架构图就像一张完整的地图,我们需要由面到点深入到图中,才能真正的了解吃透skynet,使用中才知道要注意哪些细节。
现实中了解地图中的一个地方自然是实地去走一走。了解代码框架的话当然是结合源码和文档(skynet github 上的wiki文档就写的非常不错)。
源码不止看了一遍,所以基本上都是n探,探多了就清楚自己哪些地方很熟哪些还不熟,哪些是重点,哪些使用中需要注意。
n探main
启动skynet必须携带一个config配置文件,配置项的详细介绍可以看skynet wiki,那里非常详细。
我简单介绍一下比较常用的配置项:
- thread 启动多少个工作线程。通常不要将它配置超过你实际拥有的 CPU 核心数。实际开发中可以根据业务流量把控
- bootstrap 启动的第一个服务以及其启动参数。默认配置为 snlua bootstrap ,即启动一个名为 bootstrap 的 lua 服务。通常指的是 service/bootstrap.lua 这段代码。基本上用默认的就行
- harbor 节点id,skynet cluster(master/slave)模式使用,云风大佬不推荐使用。所以一般直接配置为0单节点模式。如果需要RPC调用,可以考虑 cluster mode模式。可以读一读云风设计心路历程。
- daemon 配置 daemon = “./skynet.pid” 可以以后台模式启动 skynet 。注意,同时请配置 logger 项输出 log 。后台运行
- logger 日志文件目录。
- logservice 日志服务,通常直接用skynet自带的logger服务,不提供日志切割,可以自己配置linux上的logrotate实现日志切割。
- profile 是否统计每个服务使用cpu时间。在debugconsole中可以查看。
- preload 前置加载lua文件。通常用来加载自定义的全局工具函数
- lualoader 用哪一段 lua 代码加载 lua 服务。通常配置为 lualib/loader.lua。
- start 这是 bootstrap 最后一个环节将启动的 lua 服务,也就是你定制的 skynet 节点的主程序。默认为 main ,即启动 main.lua 这个脚本。这个 lua 服务的路径由下面的 luaservice 指定。
- cpath c服务模块查找加载路径。
- luaservice lua服务查找加载路径。
- lua_cpath 将添加到 package.cpath 中的路径,供 require 调用。
- lua_path 将添加到 package.path 中的路径,供 require 调用。
读完配置之后main函数就根据配置项做一些初始化的工作。
- 注册系统信号HUP(接收后会发送system消息给logger服务,logger接送后会重新打开日志文件,可用于日志切割。)触发信号(kill -HUP 进程号)单发,或者(pkill -HUP -f skynet.(配置文件)单发) 或者群发(pkill -HUP skynet)
- daemon守护进程。(检测skynet.pid进程号是否系统正在运行,在运行启动不了)
- 初始化harbor handle mq module timer socket
- 启动logger日志服务。
- 启动lua bootstrap服务。
- 启动 monitor timer socket worker线程。
重点讲一下worker线程初始化的配置。
1 | |
每个启动的worker线程都会绑定一个weight值。
云风写死了32个weight的配置。
在skynet_context_message_dispatch函数中,也就是worker线程从全局队列中弹出ctx mq时,会用weight值决定它本次处理的消息数量。
如上代码,n为待处理消息数量,weight>=0时,n等于n>>weight,也就是说,根据weight适配的处理规则如下:
- -1 1
- 0 n
- 1 n的2分之1
- 2 n的4分之1
- 3 n的8分之1
云风大佬这样设计是为了防止出现服务饿死的情况,在机器cpu很多的情况下也能充分利用多核优势,快速处理消息,减少cpu切换调度。
n探skynet_module
module的源码总共210行,非常简单易懂,module的的任务就是查找、加载、缓存、调用模块。
1 | |
在创建skynet_context的时候通过skynet_module_query(const char* name)函数绑定一个模块,该函数会在skynet_module_init(const char *path)传入的path路径中查找 (name).so动态库文件并且加载再绑定create,init,release,signal接口函数。然后缓存到modules结构中,以便下次使用不需要再加载动态库,提高速度。
1 | |
可以发现,云风写死了只能加载32个模块服务动态库。
1 | |
模块提供接口调用函数,其中create,init在skynet_context_new中调用,release服务退出时调用,signal是API直接调用的。
写一个模块服务需要注意的是模块名字的文件名必须是(service_名字),接口名必须是(名字_接口名),可以参考service-src/service_logger.c
1 | |
n探skynet_message,message_queue,global_queue
skynet_message
1
2
3
4
5
6struct skynet_message {
uint32_t source; //消息来源地址就是来源handle id
int session; //唯一会话id 一般用session来确定回复消息
void * data; //数据
size_t sz; //数据大小
};以上是sknyet_message的组成,其中sz中最左边的一个字节用来存放type。比如
smsg.sz = len | ((size_t)PTYPE_TEXT << MESSAGE_TYPE_SHIFT);message_queue
1
2
3
4
5
6
7
8
9
10
11
12
13struct message_queue {
struct spinlock lock; //多线程自旋锁
uint32_t handle; //绑定的ctx
int cap; //容量
int head; //队列头(pop)
int tail; //队列尾(push)
int release; //标记是否释放队列
int in_global; //是否在全局队列里
int overload; //待处理消息数量是否超过overload_threshold
int overload_threshold;//默认1024
struct skynet_message *queue; //消息队列
struct message_queue *next; //下一个message_queue
};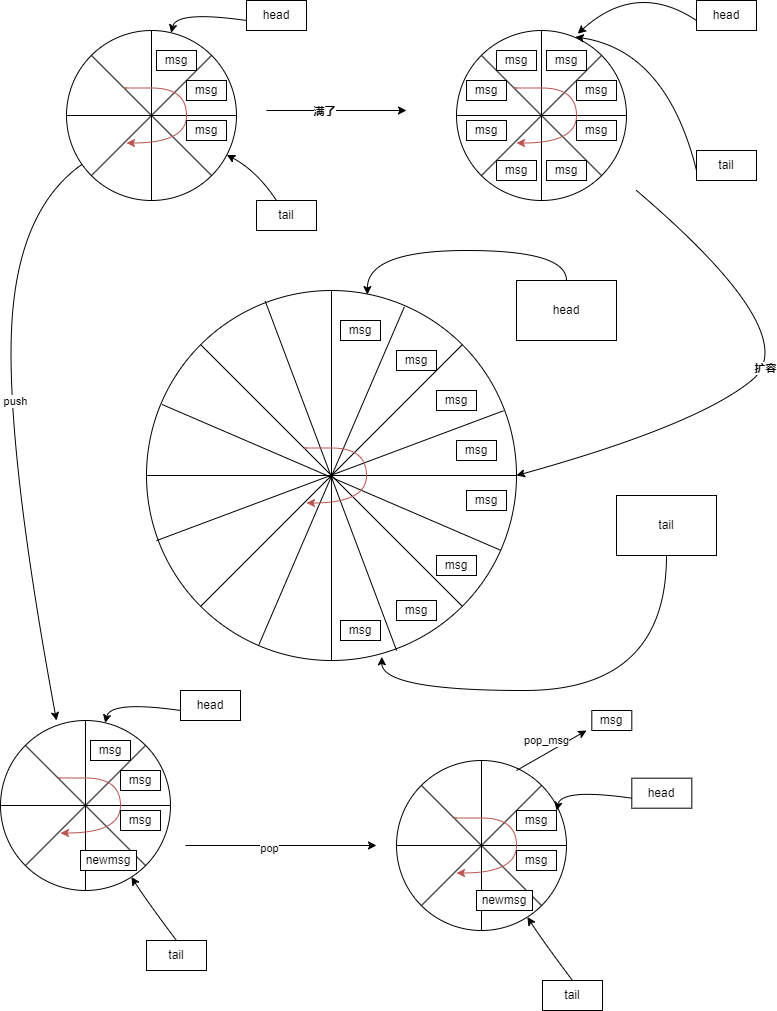
message_queue初始容量为64,当待处理消息超过容量时会进行扩容,扩容现有容量的一倍,消息队列扩容后不支持缩容量。
当有worker_thread在pop消息时会检查消息队列长度是否大于overload_threshold,大于时会标记overload待处理消息数量。1
2
3
4int overload = skynet_mq_overload(q);
if (overload) {
skynet_error(ctx, "May overload, message queue length = %d", overload);
}如果overload不等于0,会在处理消息之前打印一个日志,启到报警作用。
出现这个日志就说明这个服务的消息处理速度远远低于消息创建速度,要警惕了。
当服务退出后,worker线程就不在处理该服务的消息,会将有消息进行丢弃处理。
1 | |
丢弃处理是给消息来源方发送PTYPE_ERROR消息。
- global_queue
全局消息队列主要负责把次级消息队列(message_queue)串起来,供worker_thread消费执行。此时可以再回头是看看架构图,应该就清晰许多了😊1
2
3
4
5struct global_queue {
struct message_queue *head; //头部pop
struct message_queue *tail; //尾部push
struct spinlock lock;
};
n探skynet_context
skynet框架核心结构,源代码中遍地都是handle,其实就是服务的唯一id。
skynet_context是什么,它是sknyet中的主角,skynet中的所有服务都是skynet_context抽象的,可以说它是母体。
1 | |
可以看到skynet_context依赖了skynet_module,和message_queue。
服务创建
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58struct skynet_context *
skynet_context_new(const char * name, const char *param) {
struct skynet_module * mod = skynet_module_query(name);
if (mod == NULL)
return NULL;
void *inst = skynet_module_instance_create(mod);
if (inst == NULL)
return NULL;
struct skynet_context * ctx = skynet_malloc(sizeof(*ctx));
CHECKCALLING_INIT(ctx)
ctx->mod = mod;
ctx->instance = inst;
ctx->ref = 2;
ctx->cb = NULL;
ctx->cb_ud = NULL;
ctx->session_id = 0;
ctx->logfile = NULL;
ctx->init = false;
ctx->endless = false;
ctx->cpu_cost = 0;
ctx->cpu_start = 0;
ctx->message_count = 0;
ctx->profile = G_NODE.profile;
// Should set to 0 first to avoid skynet_handle_retireall get an uninitialized handle
ctx->handle = 0;
ctx->handle = skynet_handle_register(ctx);
struct message_queue * queue = ctx->queue = skynet_mq_create(ctx->handle);
// init function maybe use ctx->handle, so it must init at last
context_inc();
CHECKCALLING_BEGIN(ctx)
int r = skynet_module_instance_init(mod, inst, ctx, param);
CHECKCALLING_END(ctx)
if (r == 0) {
struct skynet_context * ret = skynet_context_release(ctx);
if (ret) {
ctx->init = true;
}
skynet_globalmq_push(queue);
if (ret) {
skynet_error(ret, "LAUNCH %s %s", name, param ? param : "");
}
return ret;
} else {
skynet_error(ctx, "FAILED launch %s", name);
uint32_t handle = ctx->handle;
skynet_context_release(ctx);
skynet_handle_retire(handle);
struct drop_t d = { handle };
skynet_mq_release(queue, drop_message, &d);
return NULL;
}
}创建服务会查询绑定
模块名称对应的模块库,然后调用create接口,注册handle_id,调用init接口函数。
init接口返回0表示创建成功,返回其他表示创建失败,最终创建函数返回新ctx的指针。服务销毁
skynet 销毁服务是通过skynet_handle_retire(uint32_t handle)函数执行的,不过它只是把长驻的ref给释放了,不一定在这个函数中销毁。1
2
3
4
5
6
7
8struct skynet_context *
skynet_context_release(struct skynet_context *ctx) {
if (ATOM_DEC(&ctx->ref) == 0) {
delete_context(ctx);
return NULL;
}
return ctx;
}需要当ctx.ref也就是引用计数为0时才真正销毁实例,保证多线程安全性。
n探skynet_handle
如果说skynet_context是主角,这TM就是主角们的大别墅,看见上面skynet_context创建过程有什么,skynet_handle_register这TM就相当于去别墅里去拿个房卡,这个房卡就是skynet_context.handle。
房子多大 一开始有4个房间,当来了5个人,房子就扩建了,增加原来容量的一倍,人走了,别墅不缩,别墅最大容量为16,777,215。
如果用handle查询房间会很快O1的时间复杂度,因为云风采用的是hash结构存储。房间名
1
2
3
4
5
6
7
8
9
10const char *
skynet_handle_namehandle(uint32_t handle, const char *name) {
rwlock_wlock(&H->lock);
const char * ret = _insert_name(H, name, handle);
rwlock_wunlock(&H->lock);
return ret;
}可以为服务创建一个别名,然后通过别名去找对应的handle实例,通过别名采用的是二分查找,时间复杂度是
log n,名称对比还有一个o n的时间复杂度,所以我觉得能不用别名就不用,除非那个服务很特殊,比如logger日志服务。
n探timer,timer_event,time_node,time_list
skynet定时器非常的高效,因为timer_thread只需要关心即将到期的定时事件。
timer_event
1
2
3
4struct timer_event {
uint32_t handle; //注册的handle_id
int session; //绑定会话id
};session id用于定时事件触发时,会通过消息的方式返回给handle实例,handle实例可以通过session确定定时任务触发。
time_node
1
2
3
4struct timer_node {
struct timer_node *next; //下一个节点
uint32_t expire; //过期时间
};link_list
1
2
3
4struct link_list {
struct timer_node head; //链表头
struct timer_node *tail; //链表尾
};timer
1
2
3
4
5
6
7
8
9struct timer {
struct link_list near[TIME_NEAR]; //近期链表
struct link_list t[4][TIME_LEVEL]; //散列链表
struct spinlock lock;
uint32_t time; //服务启动时间累加滴答数
uint32_t starttime; //服务启动时间
uint64_t current; //当前服务启动时间累加的时间
uint64_t current_point; //当前的系统时间
};近期链表:0-255个滴答数的定时任务会加入。特征:链表里都是触发时间相同的
散列链表:256 <= interval <= 0xffffffff 加入。 特征:链表里触发时间不一定相同
滴答数: skynet的定时器精度为0.01秒,按照它算法的定义就是0.01为1个滴答数。
到期时间:每一个加入的定时任务都会给它标记一个到期时间(加入时定时器当前滴答数+定时滴答数)。
skynet每次update都会取当前时间减去上次update时间获取流逝的滴答数。
然后把流逝的滴答数一滴答一滴答的执行。
执行过程中只关心到期间隔时间为 0 到 255 滴答数的处理。暂时不关注256 <= interval <= 0xffffffff。
滴答滴答流逝过程中,每走完一次0到255就会有一个对应的散列链表被移动(其实就是重新加入定时器,会重新给它们定位。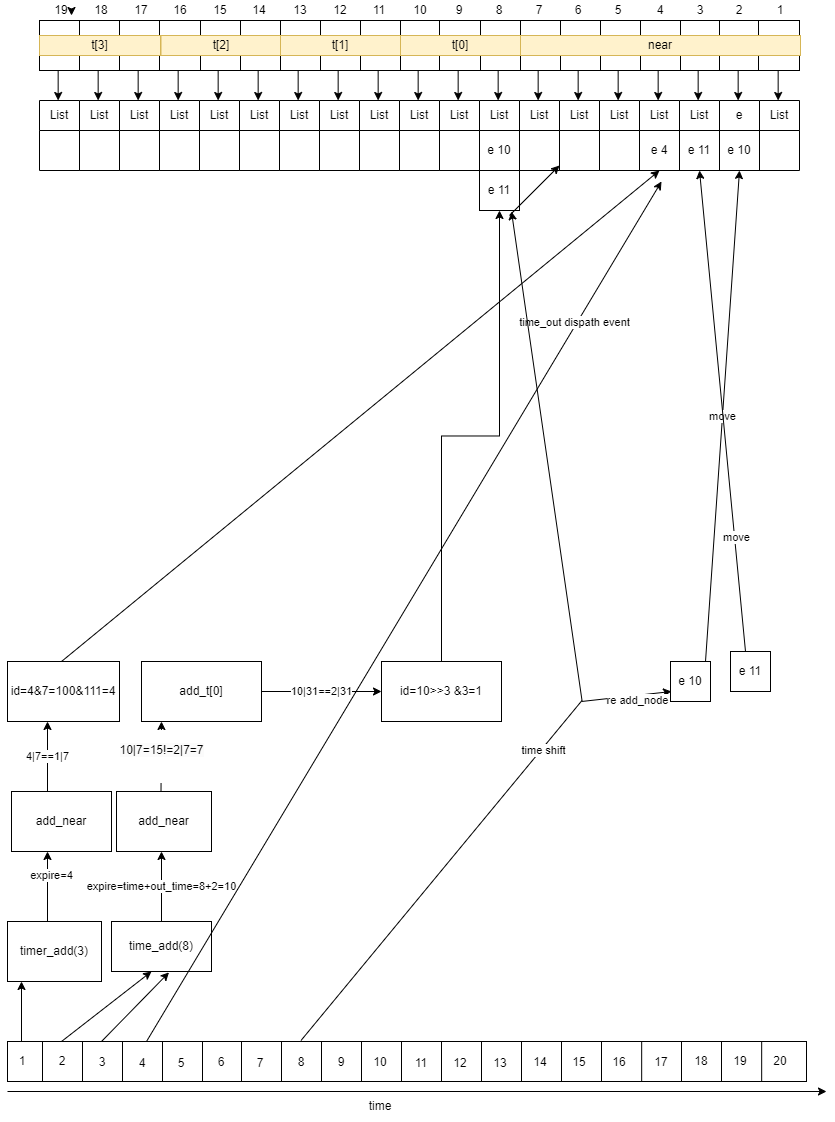
上图是我对定时器程序的简化模拟,我画的hash槽是7+3+3+3+3,skynet_time是255+64+64+64+64个哈希槽。
可以把near,t[0],t[1],t[2],t[3]想象成秒,分,时,天,周插入事件 可以说是给它找位置,秒内触发就插入秒,分内触发就插入分。
调整过程 用机械表来举例子吧,比如这一分钟的秒针走完了到了12点的位置,此时分钟指针指向下一秒钟,就要把下一分钟的事件重新分配到秒指针上。
小时,周也是这样一个逻辑,比如秒针分针都到12点,触发时针指向跳动,就要把下一个小时的事件重新分配了。
定时器只提供的注册没有提供注销,不过有sesion,在上层实现一个注销功能还是很简单的。
n探socker_server,socker_message
socket是skynet比较复杂的模块,总代码量有2千1百行。
对TCP,UDP进行了封装。
TCP FreeBSD系统下用kqueue,linux系统下用epoll,skynet epoll采用的是水平触发模式。
UDP skynet封装了链接,发送,读取回调等等。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39struct socket {
uintptr_t opaque; //handle
struct wb_list high; //高优先级写数据列表
struct wb_list low; //低优先级写数据列表
int64_t wb_size; //写数据长度
struct socket_stat stat; //链接统计信息 总读 总写 上次写的时间 上次读的时间
volatile uint32_t sending;
int fd;
int id;
uint8_t protocol;
uint8_t type;
uint16_t udpconnecting;
int64_t warn_size;
union {
int size;
uint8_t udp_address[UDP_ADDRESS_SIZE];
} p;
struct spinlock dw_lock;
int dw_offset; //偏移量n
const void * dw_buffer; //同步直写失败时,会把buffer clone到这,注册epoll写事件,异步再试
size_t dw_size;
};
struct socket_server {
volatile uint64_t time;
int recvctrl_fd; //socket thread读取管道
int sendctrl_fd; //发送管道
int checkctrl; //标记 在处理管道消息和读取网络消息来回切换
poll_fd event_fd; //create epoll的 poll_fd
int alloc_id; //用于分配id
int event_n; //网络事件数量
int event_index; //网络事件处理下标
struct socket_object_interface soi; //socket对象接口
struct event ev[MAX_EVENT]; //待处理网络事件
struct socket slot[MAX_SOCKET]; //socket 管理池
char buffer[MAX_INFO]; //tcp临时数据
uint8_t udpbuffer[MAX_UDP_PACKAGE]; //udp数据
fd_set rfds;
};socket层主要围绕读写管道、socket事件通知、处理结果下发这三个流程做一些处理。
读写管道 像listen,connenct,bind,start,close,shutdown,close,nodelay接口全部是先写到发送管道,之后socket thread再读取管道,解析请求,处理请求,再转发消息到handle实例中。
socket epoll的accept,connect,read,write事件通知处理,然后再把结果转发到handle实例中.
处理结果 转发给handle的消息定义了一系列类型,供上层去接送处理。
1
2
3
4
5
6
7#define SKYNET_SOCKET_TYPE_DATA 1
#define SKYNET_SOCKET_TYPE_CONNECT 2
#define SKYNET_SOCKET_TYPE_CLOSE 3
#define SKYNET_SOCKET_TYPE_ACCEPT 4
#define SKYNET_SOCKET_TYPE_ERROR 5
#define SKYNET_SOCKET_TYPE_UDP 6
#define SKYNET_SOCKET_TYPE_WARNING 7非常典型的上层处理方案就是云风大佬自己封装的lua层的socket.lua。
n探worker_thread
负责从全局队列中拿出次级队列,再从次级队列拿出消息进行处理。
worker线程是多个的,数量是启动配置thread设置的,每个worker_thread会根据weight适配一次处理skynet_message的数量。
n探timer_thread
timer线程是唯一的。
负责时间滴答数的向前推进、定时器事件的管理、到期事件的消息投递。
n探socket_thread
socket线程也是唯一的。
负责读取处理管道请求、读取处理socket事件,然后转发消息到相关的handle实例中。
n探monitor_thread
monitor线程也是唯一的.
负责监控worker_thread在处理消息中,是否存在阻塞的情况,就是卡,或者死循环了。
总结
整体又捋了一遍后,我发现我对skynet c层的架构更清晰也更系统全面,零零散散的知识好像一下子整合起来的😊。